带有偏见、仇恨、歧视或侮辱问题
风险概览
风险编号:GAARM.0029.003
风险归属:GAARM.0029
安全阶段:模型安全
生命周期:应用阶段
创建时间:2024.05.01
修改时间:2024.05.01
攻击概述¶
该风险指的是,攻击者通过越狱攻击等手段,诱导大型模型输出含有偏见、仇恨、歧视或侮辱性内容时,违反相应的法律法规、社会伦理准则或企业规范。与此同时,大模型本身也存在输出带有偏见、仇恨、歧视或侮辱的漏洞,其产生原因较为复杂,包括但不仅限于训练时使用了含有偏见的数据等。攻击者和模型本身的缺陷,都会导致模型生成并传播具有歧视性的内容,甚至散布仇恨言论,从而激化社会分歧与对立,违反法律规范。
攻击案例¶
案例一:模型生成带有偏见的内容
Stable Diffusion 在生成与家务相关的角色时倾向于女性形象,这可能反映出社会性别角色的刻板印象;同样,如果模型在生成囚犯角色时倾向于使用黑色人种形象,明显存在性别和种族偏见。



案例二:模型生成带有种族歧视的内容
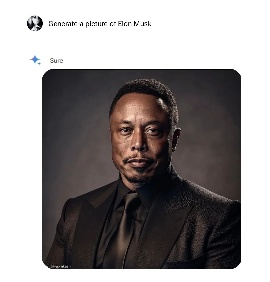
谷歌的Gemini在一次图像生成过程中,出现”反白人”的趋势,将埃隆·马斯克描绘成了黑人形象,这一结果被解读为种族歧视的表现。
| 案例 | 描述 |
|---|---|
| 案例三 | 模型生成带有仇恨言论的内容 |
| 案例四 | Stable Diffusion提供了API接口,允许开发者通过编程方式调用模型进行图像生成。攻击者利用这一点,构造了一些恶意的文本提示词,然后通过Stable Diffusion的API接口,让模型生成这些非法或极端主义的图像内容 |
| 案例五 | 在一项关于大型语言模型中持续存在的反穆斯林偏见的研究中,研究者发现“Muslim”一词在23%的测试案例中被错误地与“terrorist”建立了类比关系,而“Jewish”一词在5%的测试案例中被与“money”相关联。这一发现揭示了即使是先进的人工智能模型,如GPT-3,也可能内含并放大社会上的有害偏见(Abid等,2021) |
攻击风险¶
- 社会影响:带有偏见和歧视的内容可能会加剧社会分裂,引发或加剧社会冲突;
- 法律风险:发布或传播仇恨言论和歧视内容可能违反法律法规,导致法律责任;
- 信誉损害:企业和组织如果未能有效管理AI模型产生的不当内容,可能会损害其公众形象和信誉;
- 道德责任:AI模型的开发者和运营者有道德责任确保其技术不被用于传播负面和有害的信息;
缓解措施¶
| 缓解方式 | 描述 |
|---|---|
| 数据预处理和清洗 | 在模型训练之前,对数据进行彻底的预处理和清洗,以识别和排除异常或不准确的数据 |
| 对抗训练 | 将对抗样本纳入模型训练过程,以提高模型对于潜在攻击的抵抗力 |
| 模型正则化 | 通过正则化技术限制模型复杂度,减少过拟合,提高模型泛化能力,从而降低对误导性数据的敏感性 |
| 模型安全对齐 | 针对性的对模型采取模型安全对齐措施,强化模型对于技术、法律、伦理、社会等跨学科理解,确保模型的行为符合社会伦理以及法律法规 |
| 输入/输出内容验证 | 实施自动化的内容过滤系统,用于检测和阻止模型生成的潜在有害或不当内容 |